实例生命周期
此章节列出应用实例即集群几个主要操作的基本流程图。
创建集群
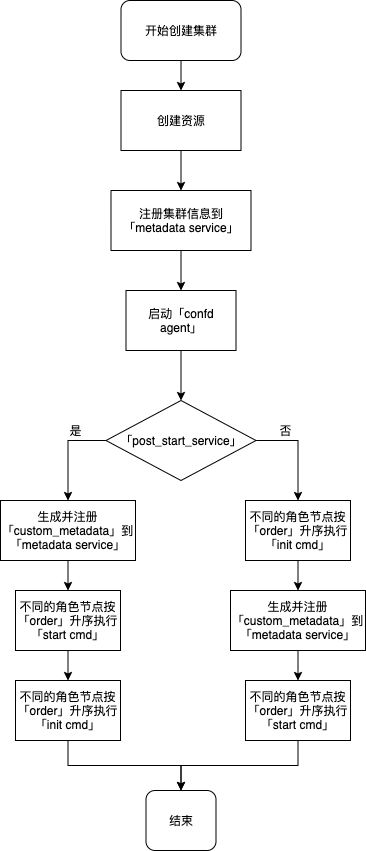
- 创建当前集群所有节点的资源如云服务器、硬盘、IP 地址等;
- 将本集群中所有信息注册到 metadata service 中;
- 启动所有节点的 confd agent,监控 metadata service 中本集群信息的变化并按照 /etc/confd 下的模板 (toml、tmpl) 定义刷新配置;如果 toml 文件里定义 reload_cmd 且配置确实发生变更则相应地执行该命令;
- 执行 init 和 start 中定义的 cmd,按照 init 中 post_start_service 的定义顺序执行,如果 post_start_service 为 true 则表示 init 在 start 后执行;不同 role 节点相同命令执行顺序按照 order 的定义从小到大依次执行,默认为0(最早执行),相同 order 的节点并行执行。
删除集群
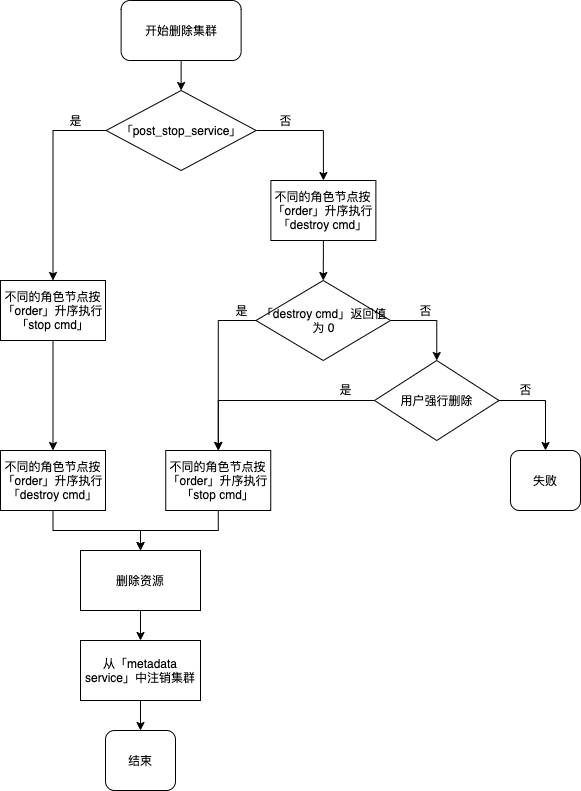
- 如果待删除的节点定义了 destroy service,则从第 3 步开始执行;如果没有则执行第 2 步和最后一步;
- 不同角色节点按照 order 升序执行 stop cmd;
- 如果待删除节点 destroy service 里定义了 post_stop_service 为 False,则从第 5 步开始执行;否则执行第 4 步和最后一步;
- 待删除的不同角色按照 order 升序执行 stop cmd,然后按照 order 升序执行 destroy cmd;
- 待删除的不同角色按照 order 升序执行 destroy cmd;依据返回值正常 (0) 或非正常 (非0) 决定下一步,此处如此设置是提供一种保护措施,您可以在 destroy 命令里查看能否删除该节点或集群,以预防数据丢失;
- 如果 destroy cmd 返回非正常且用户不选择强行删除,则此任务失败且终止;
- 如果 destroy cmd 返回正常或者在不正常情况下用户选择强行删除,则不同角色节点按照 order 升序执行 stop cmd;
- 删除当前集群所有资源,并且将本集群中所有信息从 metadata service 中注销。
关闭集群

启动/恢复集群

增加节点
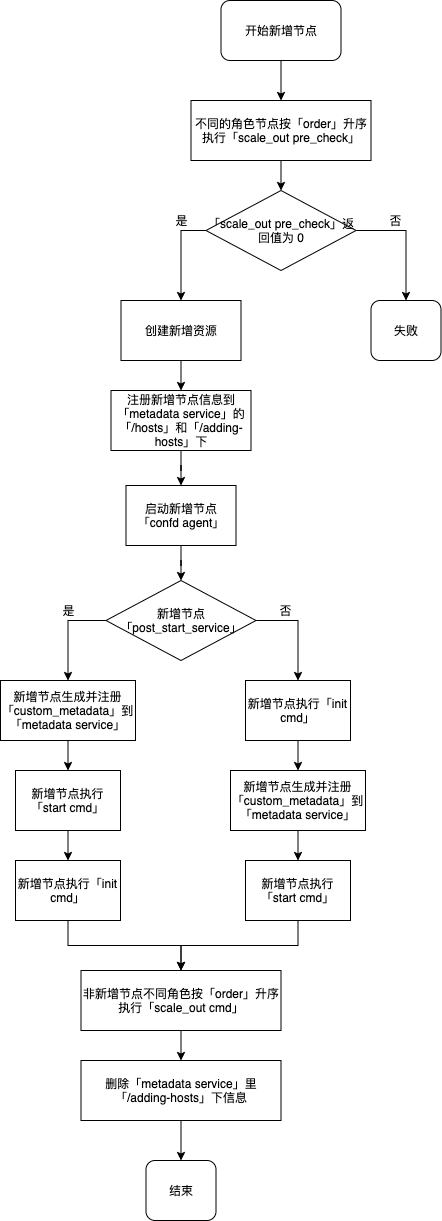
新增角色节点需支持横向伸缩,即定义了 scale_horizontal 的 advanced_actions,参见 云应用开发模板规范 - 完整版。
- 创建新增节点的资源如云服务器、硬盘、IP 地址等;
- 注册新增节点的信息到 metadata service 中即 /hosts 下,同时注册到 /adding-hosts 这个临时目录下 (注:应用的云服务器可以从这个临时目录获取信息并执行横向扩容之前预处理操作等);
- 由于 metadata service 中集群信息发生改变,因此非新增节点可能会同时更新配置。如果 toml 文件里定义 reload_cmd 且配置确实发生变更则执行该命令;
- 启动新增节点的 confd agent,同时更新自身配置信息并执行 reload_cmd;
- 执行新增节点 init 和 start 中定义的 cmd,按照 init 中 post_start_service 的定义顺序执行,不同角色节点相同命令执行顺序按照 order 的定义从小到大依次执行,默认为0(最早执行),相同 order 的节点并行执行;
- 执行非新增节点(即集群中除新增节点外其它节点,通过nodes_to_execute_on指定在某几个节点上执行) scale_out 中定义的 cmd;
- 删除 metadata service 中 /adding-hosts 这个临时目录下的内容;
- 由于 metadata service 中集群信息发生改变,因此各个节点可能会同时更新配置。如果 toml 文件里定义 reload_cmd 且配置确实发生变更则执行该命令。
删除节点
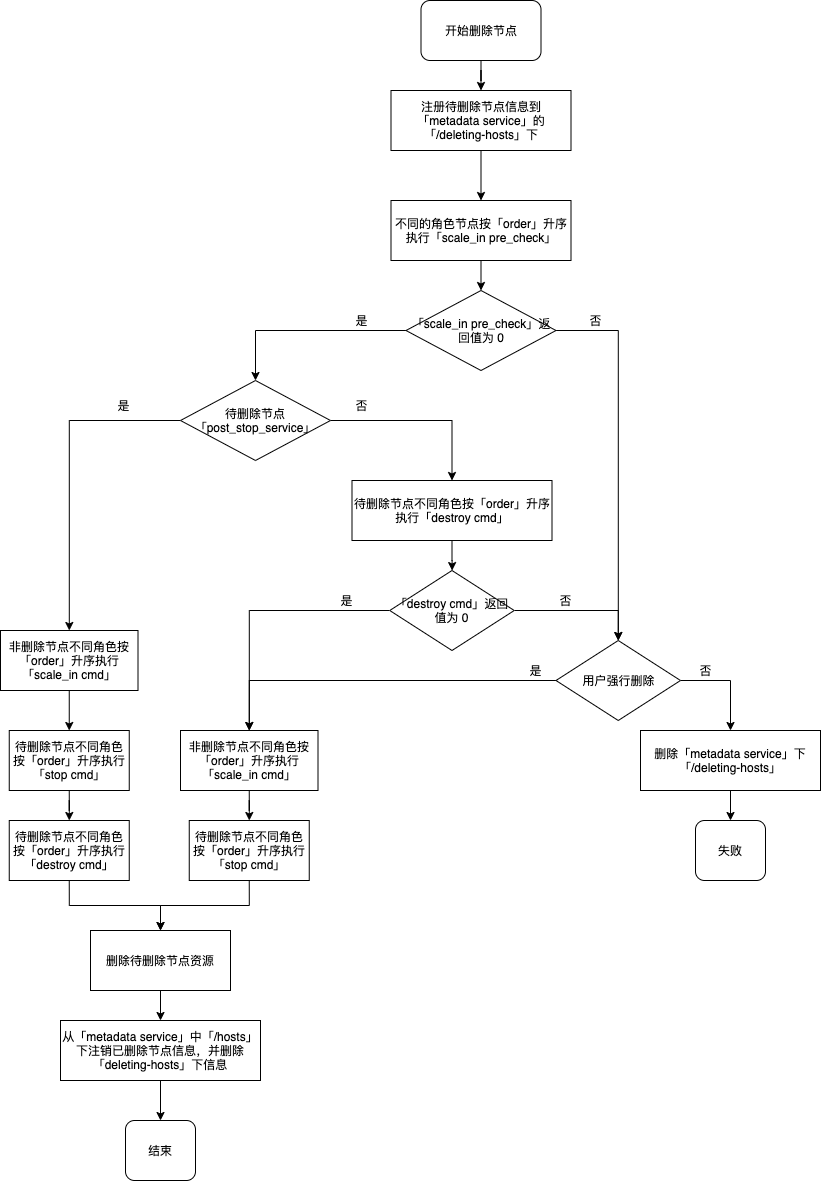
待删除角色节点需支持横向伸缩,即定义了 scale_horizontal 的 advanced_actions。
- 注册待删除节点的信息到 metadata service 的 /deleting-hosts 这个临时目录下。
- 由于 metadata service 中集群信息发生改变,因此所有节点可能会同时更新配置。如果 toml 文件里定义 reload_cmd 且配置确实发生变更则执行该命令;
- 待删除节点定义了 destroy service 则从第 5 步开始执行操作,否则执行第 4 步和最后三步;
- 非删除节点不同角色按照 order 升序执行 scale_in cmd,然后待删除节点不同角色按照 order 升序执行 stop_cmd;
- 如果待删除节点 destroy service 里定义了 post_stop_service 为 False,则从第 7 步开始执行;否则执行第 6 步和最后三步;
- 非删除节点不同角色按照 order 升序执行scale_in cmd;然后待删除节点不同角色按照 order 升序执行 stop cmd,然后按照 order 升序执行 destroy cmd;
- 待删除的不同角色按照 order 升序执行 destroy cmd;依据返回值正常 (0) 或非正常 (非0) 决定下一步,此处如此设置是提供一种保护措施,您可以在 destroy 命令里查看能否删除该节点,以预防数据丢失;
- 如果 destroy cmd 返回非正常且用户不选择强行删除,则此任务失败且终止,同时删除 metadata service 临时目录 /deleting-hosts 下信息;
- 如果 destroy cmd 返回正常或者在不正常情况下用户选择强行删除,则不同角色节点按照 order 升序执行 scale_in cmd,然后个节点按 order 升序执行 stop cmd;
- 删除集群中这些节点资源;
- 将删除了的节点信息从 metadata service 中注销并且删除临时目录 /deleting-hosts 下信息;
- 由于 metadata service 中集群信息发生改变,因此剩余所有节点可能会同时更新配置。如果 toml 文件里定义 reload_cmd 且配置确实发生变更则执行该命令。
纵向扩容/更改云服务器类型
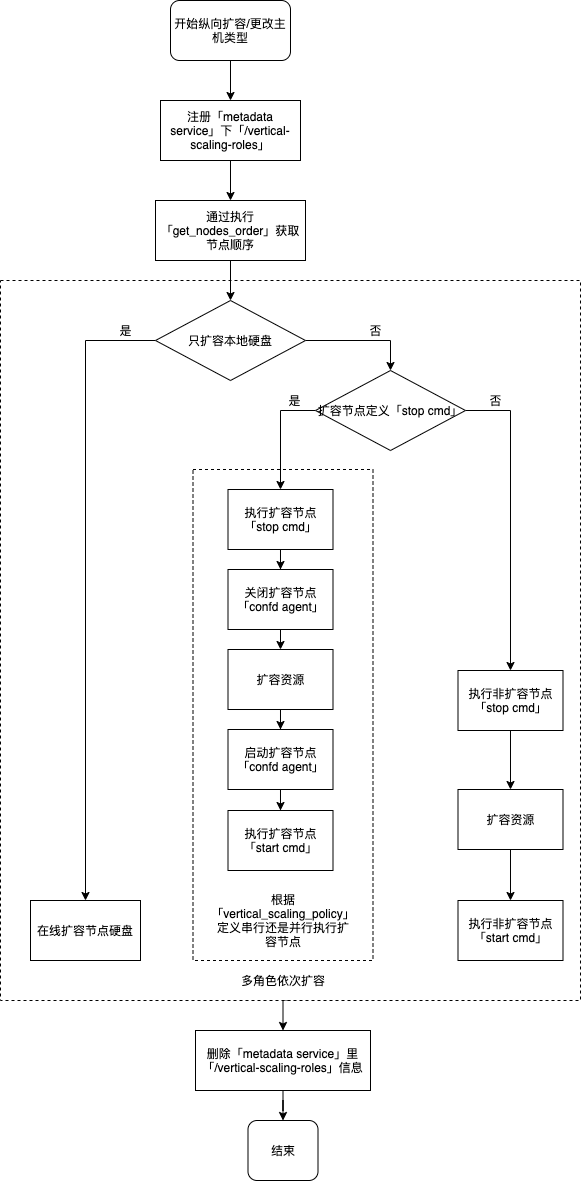
- 注册扩容角色到 vertical-scaling-roles
- 如果只扩容硬盘则直接并行执行在线扩容,然后执行最后两步;
- 如果待扩容节点定义了 stop service,则执行第 4 步和最后两步;否则执行第 5 步和最后两步;
- 按照 vertical_scaling_policy 的定义顺序执行 (sequential) 或 并行执行 (parallel) 以下操作:执行待扩容节点 stop cmd;扩容节点;执行扩容节点 start cmd;
- 执行非扩容节点的 stop cmd;然后扩容节点;最后执行非扩容节点 start cmd;
- 更新扩容节点的信息到 metadata service 中,并删除 vertical-scaling-roles;
- 由于 metadata service 中集群信息发生改变,因此所有节点可能会同时更新配置。如果 toml 文件里定义 reload_cmd 且配置确实发生变更则执行该命令。
注: 如果扩容过程中发生异常, vertical-scaling-roles 也会被删除
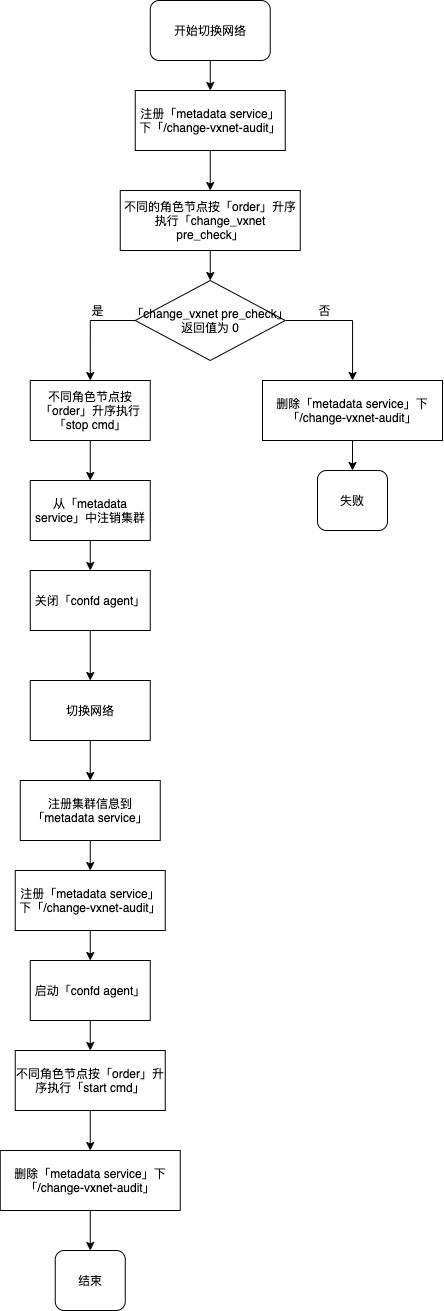
切换网络
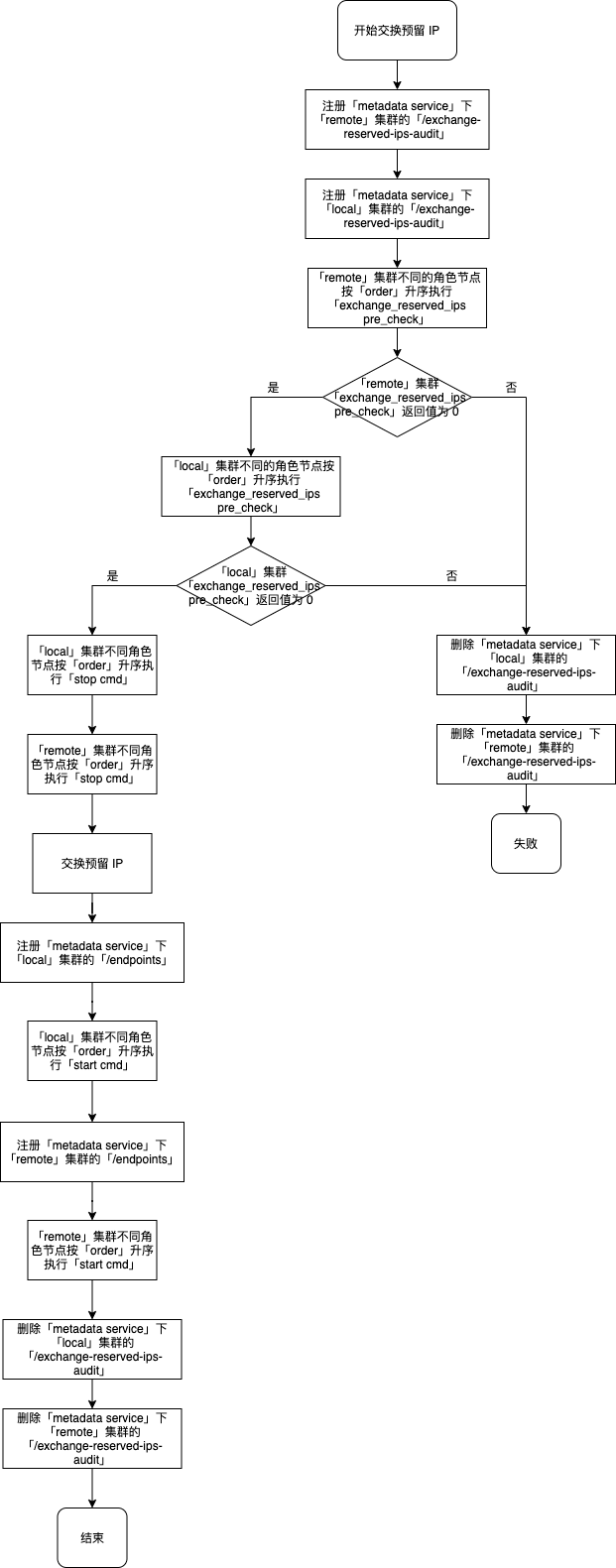
交换预留 IP
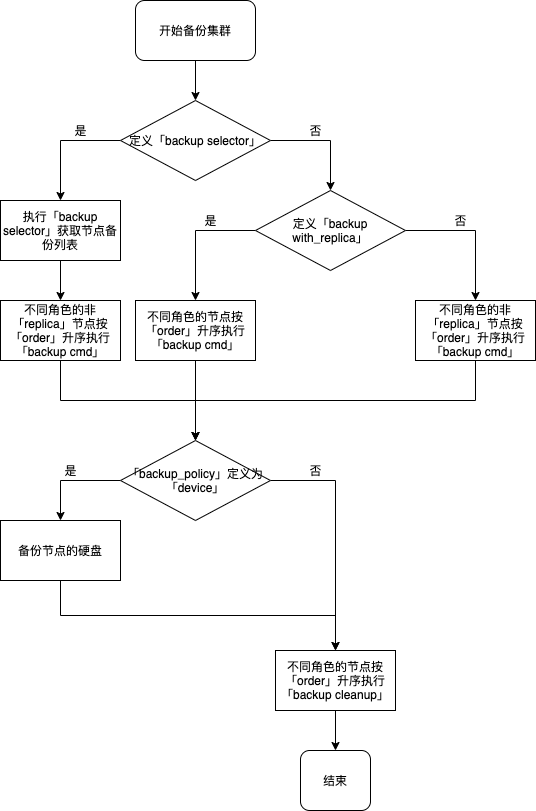
备份集群
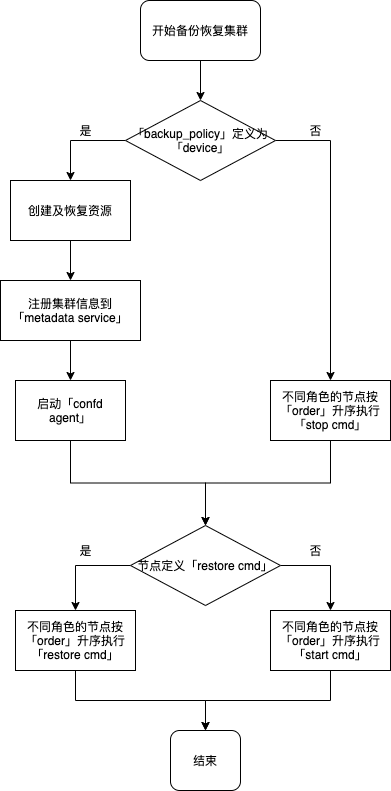
备份恢复集群
并行升级
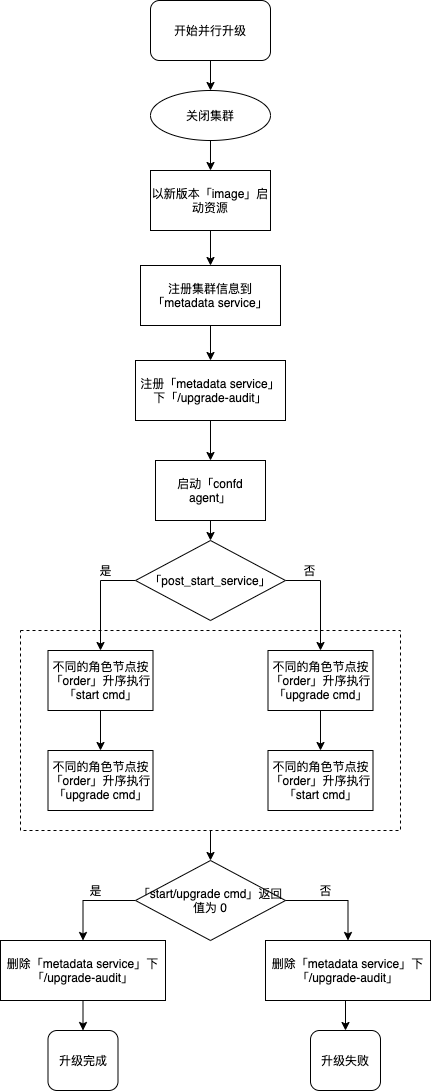
- 关闭集群节点;
- 以新版本镜像启动节点;
- 启动所有节点的 confd agent,监控 metadata service 中本集群信息的变化并按照 /etc/confd 下的模板 (toml、tmpl) 定义刷新配置;如果 toml 文件里定义 reload_cmd 且配置确实发生变更则相应地执行该命令;
- 执行 start 和 upgrade 中定义的 cmd,按照 upgrade 中 post_start_service 的定义顺序执行,如果 post_start_service 为 true 则表示 upgrade 在 start 后执行;不同 role 节点相同命令执行顺序按照 order 的定义从小到大依次执行,默认为0(最早执行),相同 order 的节点并行执行;
- 如果第 4 步中的命令执行后的返回值非0,则此次升级任务失败,需要手动关闭集群并执行第 6 步降级操作;
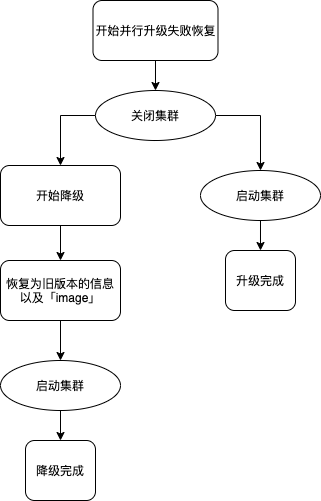
- 集群节点以旧版本镜像启动;
- 启动所有节点的 confd agent,监控 metadata service 中本集群信息的变化并按照 /etc/confd 下的模板 (toml、tmpl) 定义刷新配置;如果 toml 文件里定义 reload_cmd 且配置确实发生变更则相应地执行该命令;
- 不同的角色节点按 order 升序执行 start 中定义的 cmd。
注: 第 1 步到第 4 步的流程,按照 upgrading_policy 的定义, 顺序执行 (sequential) 或 并行执行 (parallel)
并行升级失败恢复
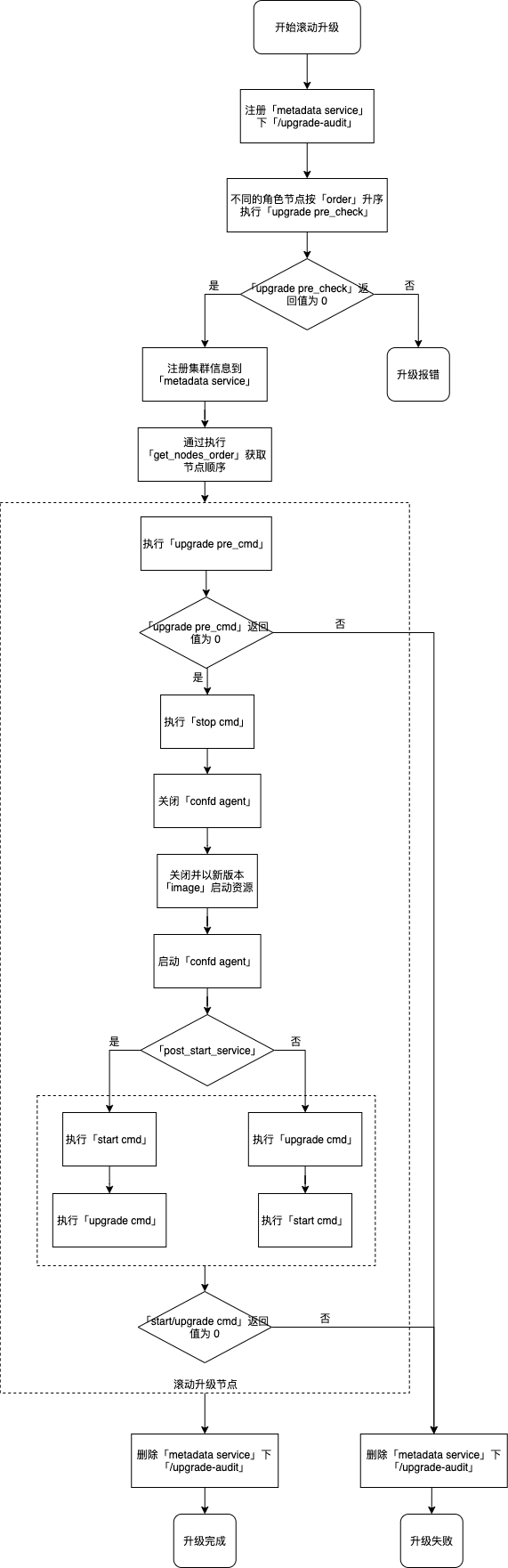
滚动升级
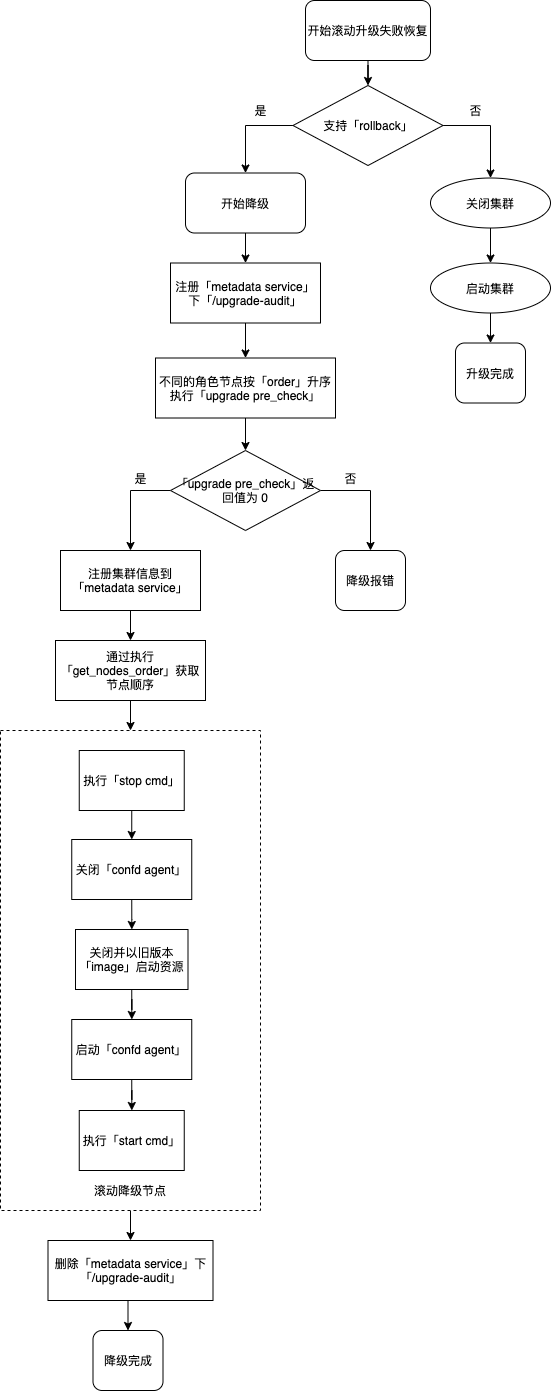
滚动升级失败恢复
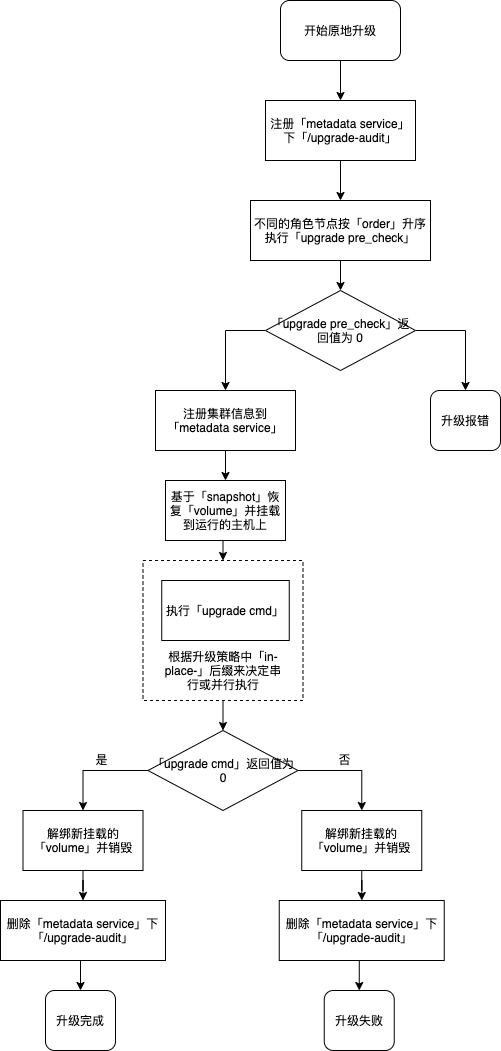
原地升级
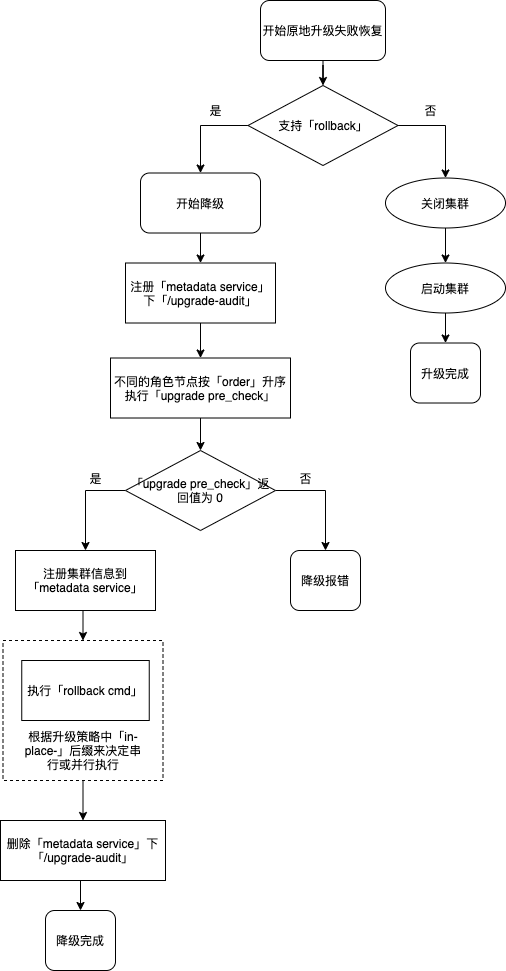
原地升级失败恢复