部署 Inference Engine 应用
通过 AppCenter 管理控制台,您可以快速部署 Inference Engine 应用。本小节主要介绍如何快速部署 Inference Engine 应用。
前提条件
操作步骤
-
登录管理控制台。。
-
在左上方的控制台导航栏中,选择产品与服务 > 人工智能(AI) > Inference Engine,进入 Inference Engine 管理页面。
-
点击立即部署,进入应用部署页面。
-
选择区域。 根据就近原则,选择实例所在区域。
-
配置实例基本属性、应用版本、网络信息、环境参数等信息。
a. 基本设置
b. 模型服务节点设置
c. 模型库节点配置
d. 网络设置
e. 服务环境参数设置
f. 用户协议
-
确认配置和费用信息无误后,点击提交,创建服务。
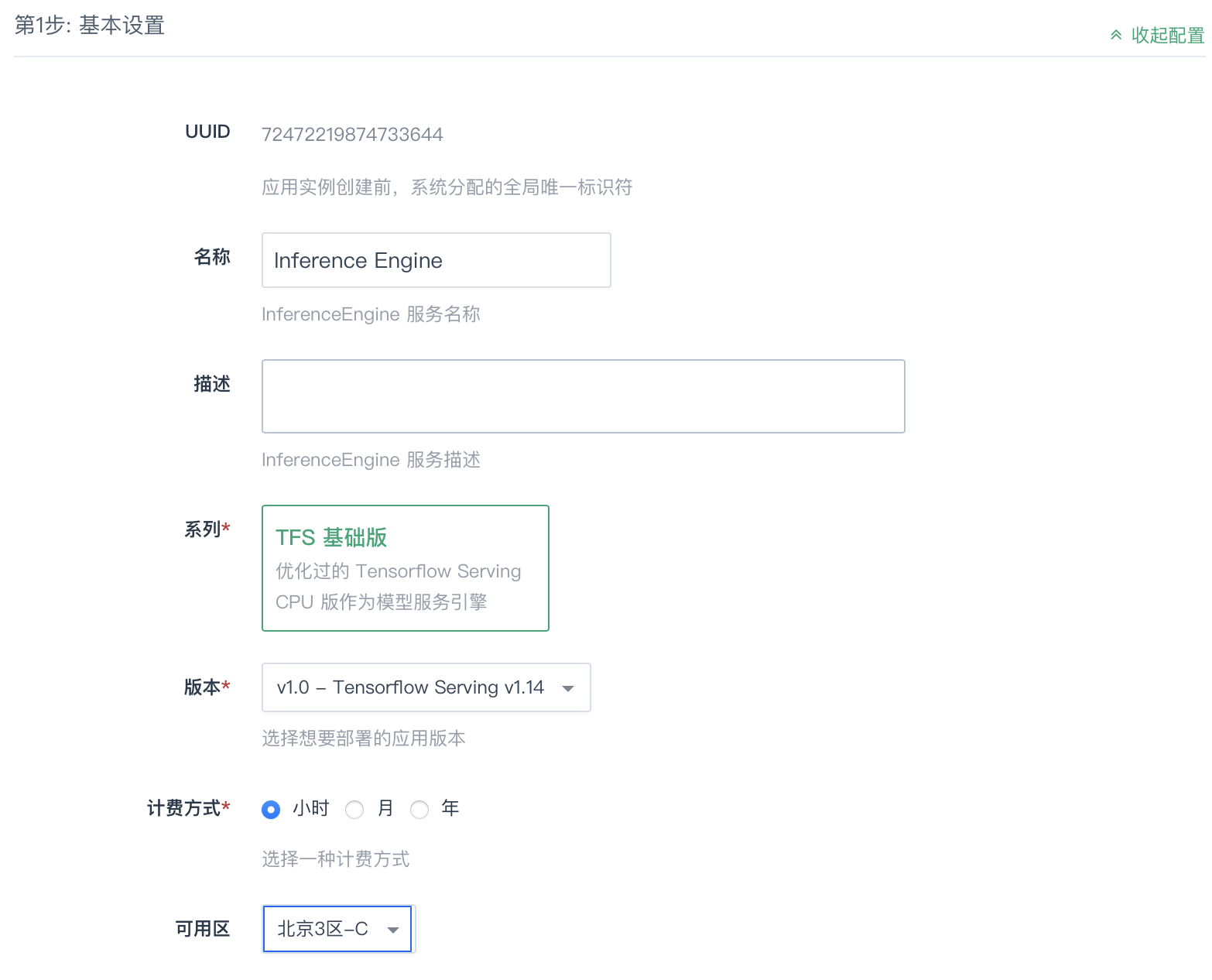
基本设置
集群名称、网络、版本、计费方式等基本信息配置。
| 参数 | 参数说明 |
|---|---|
| UUID | 系统默认分配的全局唯一标识码,不可修改。 |
| 名称 | (可选)输入推理引擎服务的名称。Deep Learning。 |
| 描述 | (可选)对推理引擎服务的简要描述。 |
| 系列 | 选择推理引擎服务的系列,只能选基础版。 |
| 版本 | 选择想要部署的应用版本,根据所选系列不同,可选版本不同。 |
| 计费方式 | 选择计费方式,可选择按小时/月/年或按合约计费。 |
| 可用区 | 目前可选择区域有上海1区、广东2区、北京3区。 |
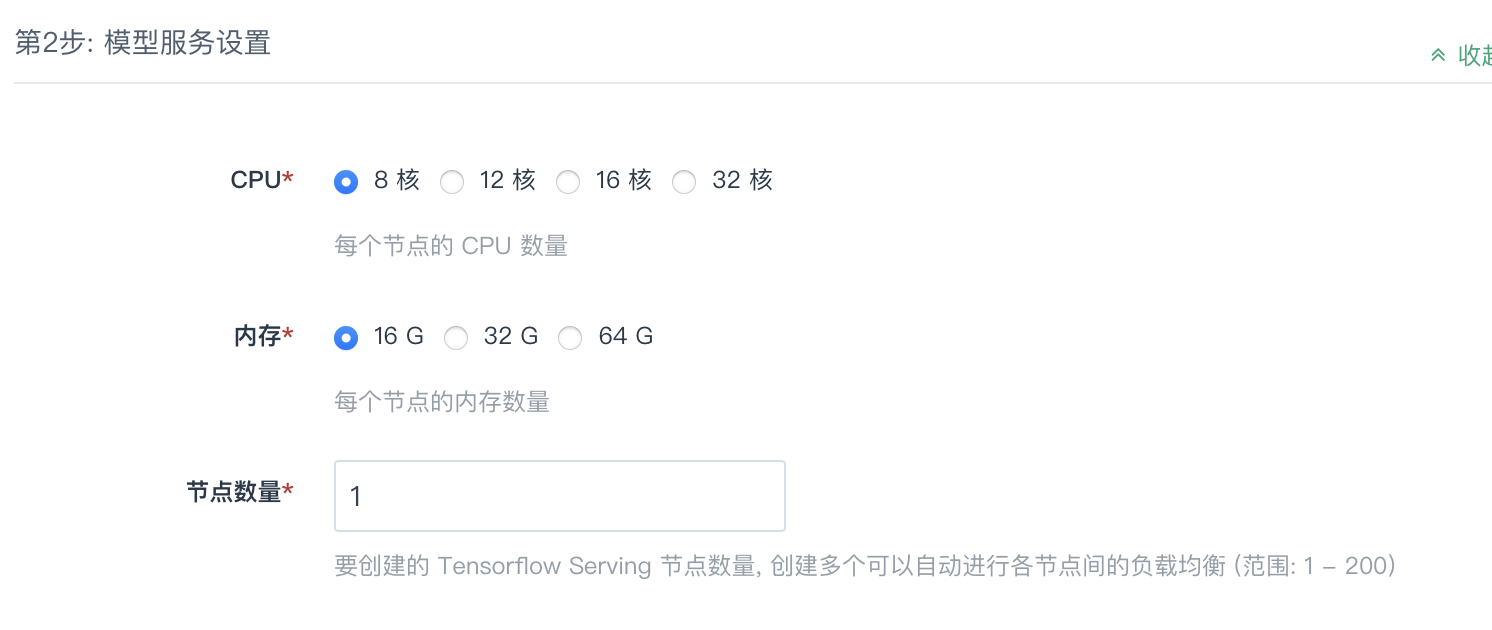
模型服务节点设置
模型服务节点会自动选择当前区最新的 CPU 用于推理,pek3 及 sh1 区均为具有推理加速能力的CascadeLake。
| 参数 | 参数说明 |
|---|---|
| CPU | 每个节点的 CPU 数量。 |
| 内存 | 每个节点的内存数量。 |
| 节点数量 | 要创建的 Tensorflow Serving 节点数量, 创建多个可以自动进行各节点间的负载均衡 (范围: 1 - 200)。 |
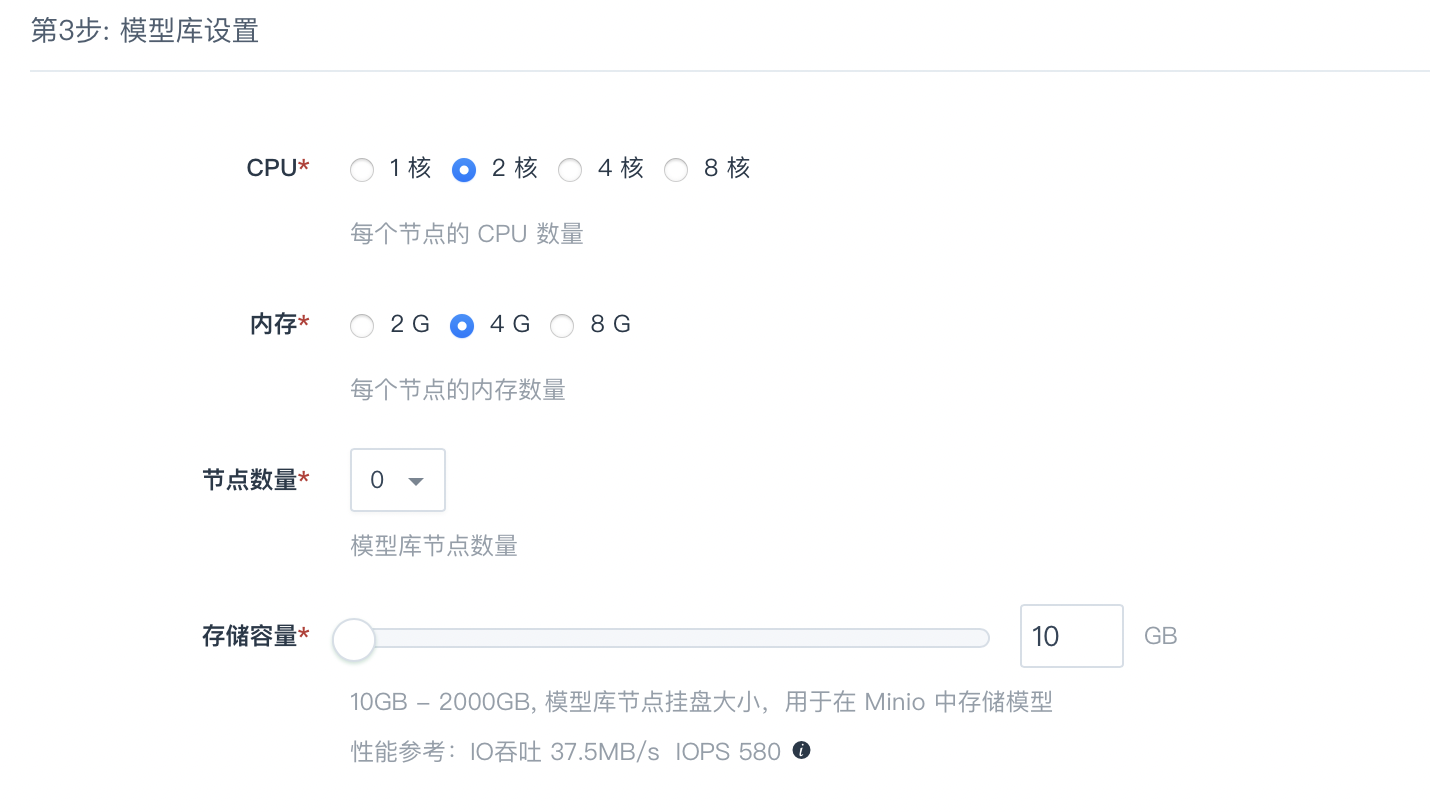
模型库节点配置
| 参数 | 参数说明 |
|---|---|
| CPU | 每个节点的 CPU 数量。 |
| 内存 | 每个节点的内存数量。 |
| 节点数量 | 模型库节点数量。 |
| 存储容量 | 10GB - 2000GB, 模型库节点挂盘大小,用于在 Minio 中存储模型。 |
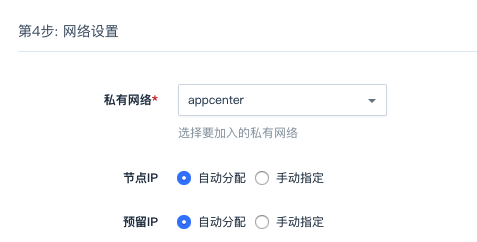
网络设置
通过为集群设置独享私有网络,便于网络过滤控制,且不影响其它私有网络的设置,可确保数据库的对不同业务进行网络隔离。数据库集群仅可加入已连接路由器的私有网络,且需确保私有网络的 DHCP 处于打开状态。
| 参数 | 参数说明 |
|---|---|
| 私有网络 | 选择私有网络。 |
| 节点 IP | 配置节点 IP 地址。自动分配。手动配置需为各节点配置 IP。 |
| 预留 IP | 配置集群预留高可用 IP 地址。自动分配。手动配置需为集群配置高可用写 IP。 |
说明:
配置的私有网络部署方式与*集群部署方式必须一致,即选择的集群部署方式为
多可用区部署,则该集群仅能选择多可用区部署的私有网络。
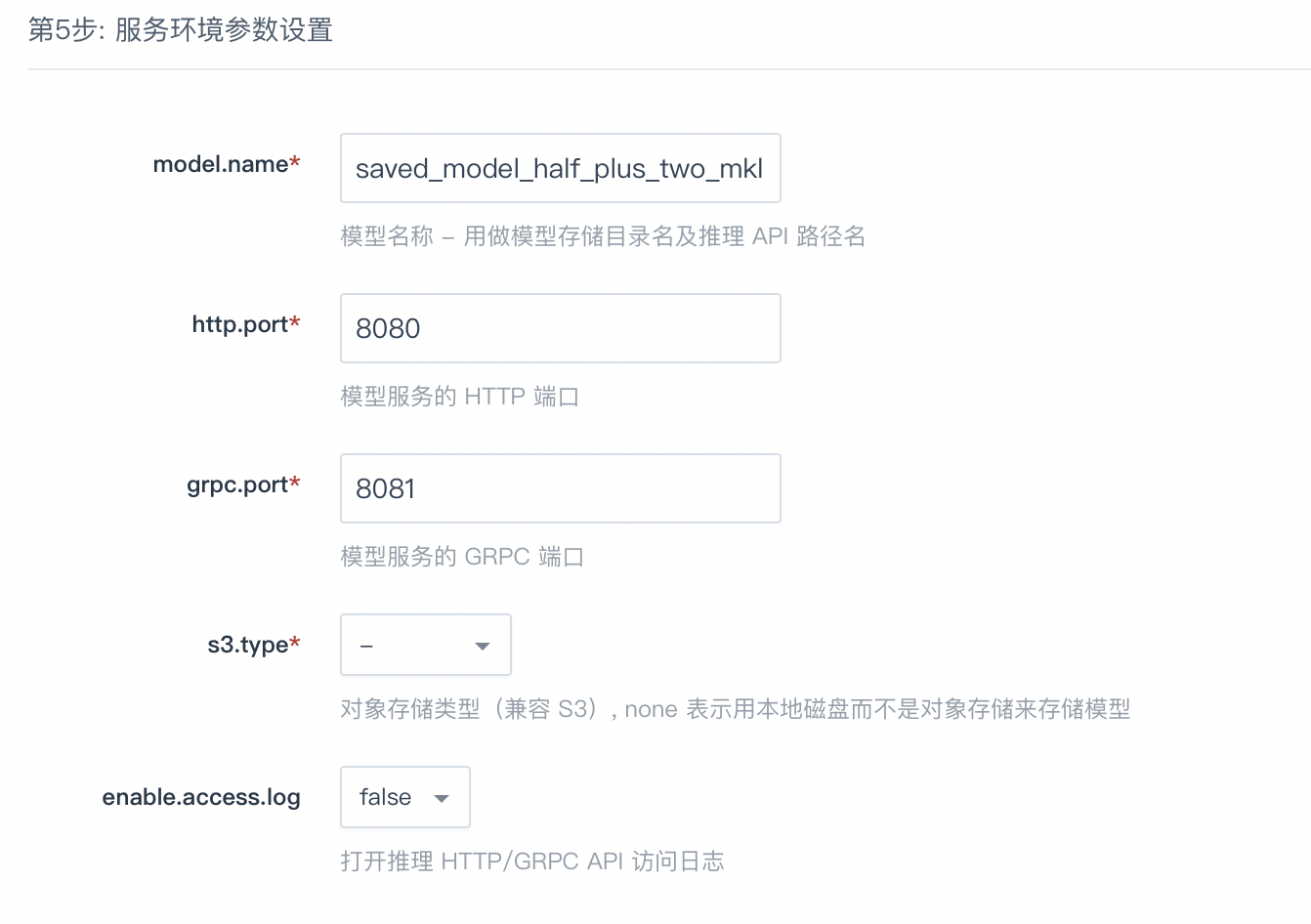
服务环境参数设置
-
model.name
该参数为模型名称,将被用作存储模型的目录名以及推理 API 的路径名:
# 模型存储在本地磁盘 /data/models/saved_model_half_plus_two_mkl /data/models/resnet # 调用模型 saved_model_half_plus_two_mkl 的 HTTP API curl -d '{"instances": [1.0, 2.0, 5.0]}' -X POST http://<Any Node IP>:8080/v1/models/saved_model_half_plus_two_mkl:predict # 调用 resnet 模型的 HTTP API curl -d '{"instances": ["b64":"<base64 encode picture>"]}' -X POST http://<Any Node IP>:8080/v1/models/resnet:predict -
http.port/grpc.port
模型 HTTP/GRPC 服务暴露端口 , 需要注意的是不能设为 8500 及 8501 这两个 Tensorflow serving 保留端口
-
enable.access.log
打开此开关将能查看推理 HTTP/GRPC API 的访问日志,可以看到每个推理请求由后端哪个节点处理。
用户协议
阅读云平台 AppCenter 用户协议,并勾选用户协议。
